作者:Jeff Pan
转载请联系作者(kevinjjp@gmail.com)或在下方留言,侵权必究。
1. 介绍
当前成熟的语音合成前段框架大体采用的是模块化的前端,按照固定的pipeline逐一得出相应模块的结果,加入到最终的语言学特征中, 如下:
\[|TN| \rightarrow |Word Parser| \rightarrow |POS| \rightarrow |G2P| \rightarrow |Prosody| \rightarrow |PostFixing|\]POS: part-of-speech 词性
G2P: grapheme to phoneme 字形到字音映射
这种结构的好处在于:
- 鲁棒性比较高
- 方便debug和tuning,能够快速定位到错误位置并修正
- 每一个模块可以单独进行调优和训练
- 对于不同语言,可以根据需求进行模块顺序的调整
- 模块之间耦合度低,彼此之间不会有很大的影响
这些特征很符合工程化的要求,因此被各大语音厂商采用并商业化。 基本在NN(神经网络)火起来前,大部分的TTS产品的前端都采用了此类结构。
但是这样过度细化的前端结构也会带来一些问题:
- 每个模型单独训练和调优都需要独立完成,会耗费更多的时间
- 每个模型都需要对应的人工标注数据,会耗费更多的资金
- 多个模型会造成巨大的footprint。并且当模型是非NN模型时(比如CRF,ME等),其footprint会随着训练语料的增多而变大
因此,鉴于目前NN的大热,一个基于NN的端到端(end-to-end)的TTS前端结构似乎是一个很有意思的想法。
2. 几种End-to-End的构想
2.1 text to acoustic feature
直接从文本到声学特征是一个end-to-end很直观的构想,它抛弃了传统的TTS前后端的概念,直接一步到位。
具体实现是:
\[TEXT \rightarrow Model_{end-to-end} \rightarrow Acoustic Feature \rightarrow Vocoder \rightarrow WAV\]这样的构想看起来很美好,非常的简洁。但是实际实现起来难度很大, 主要是由于文本层面的特征信息过少,直接映射成声学特征可能需要极为复杂的网络结构,难以调参和训练。
2.2 text to linguistic feature/middle vector
其思想是替代TTS的前端。目前已经实现的有:
-
百度(baidu)的deep voice (text to middle vector)
V1(非end-to-end) https://arxiv.org/pdf/1702.07825.pdf
V2(非end-to-end) https://arxiv.org/pdf/1705.08947.pdf
V3(end-to-end)https://arxiv.org/pdf/1710.07654.pdf
V3采用的encoder-decoder + converter + vocoder的结构
其他的一些结构:
-
基于BLSTM的结构化输出层 (BLSTM-SOL-E)
http://www.isca-speech.org/archive/Interspeech_2017/pdfs/0949.PDF
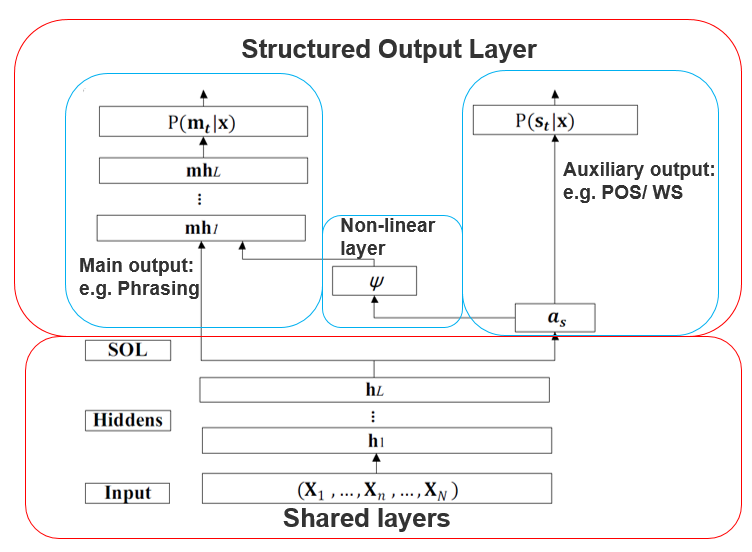
输出层采用了主任务+辅任务的形式,辅任务的输出通过一个非线性变化加入到主任务的中间层输入中。多任务共享前几层的网络权值。
-
层级结构的多任务网络
https://arxiv.org/pdf/1611.01587.pdf
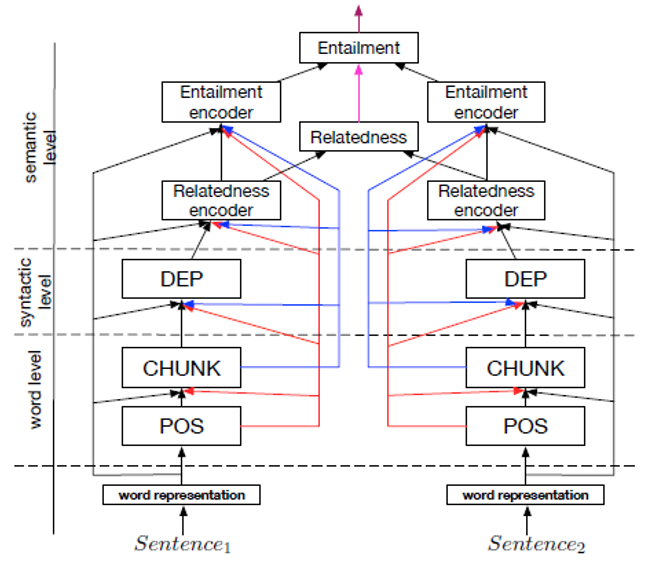
该结构的假设是各个NLP任务之间存在着必然的层级关系(类似于前文所述的pipeline结构),因此可以将多个网络串联成一个大的网络,其中的隐层输出可以理解为各个NLP任务的结果。 整个网络在训练时,是逐一训练而不是联合训练的,但是在解码(decode)时是一次性解码的。
3. End-to-End待解决的问题
在产品化中,end-to-end面临着一些特有的问题:
3.2 如何在不重新训练模型的情况下进行tuning?
因为神经网络的问题在于结果不可控,因此难免出现一些预测错误。放在从前,这些错误可以通过调整特定的模块进行处理,但是在end-to-end的架构下,这种调优变得impractical。 设计一个优雅的调优策略是亟待解决的问题。
在百度的deep voice v3中,采用的对读音tuning的办法是在训练时同时加入phoneme embedding的输入。这样可以在调整读音时,强行输入需要的读音的embedding即可。
3.1 如何解决错误累积的问题?
由于上述的end-to-end结构都是类似于将多任务bundle在一起,这样会导致前序的错误累积到后续的层级。这会造成一些不可预知的错误,并且难以追溯到错误的引发点。
一种直观的解决方案是,我们不采用结构化的输出或者层级预测的网络结构,而是采用一个网络,分别去预测不同的NLP任务。 比如一个$256\times256\times256$的BLSTM网络,同时预测多任务。但是根据 Søgaard and Goldberg(http://anthology.aclweb.org/P16-2038) 在2016年的论文中得出的结论,在不同层级预测多任务比在相同层级更准确,加上其他以层级预测的网络为基础的论文效果,这种同一网络同一层级预测多任务的方法似乎并不可行。
转载请联系作者(kevinjjp@gmail.com)或在下方留言,侵权必究。